<
>

最近研究开源深度学习语音合成,试用了百度飞桨(PaddleSpeech),测试了一下几个官方提供的模型包的性能。结论是tts-onnx模式速度快,但是只能单纯合成中文,tts模式速度满,但是有一个模型支持中英文混合和文本的合成,性能差距可达5.4倍。
测试是在我的笔记本电脑上,数据如下:
OS: Ubuntu 22.04 jammy
Kernel: x86_64 Linux 5.17.0-1025-oem
CPU: Intel Core i7-6700HQ @ 8x 3.5GHz [36.0°C]
GPU: NVIDIA GeForce 940M
RAM: 8G
executor = TTSExecutor()
executor.task_resource = CommonTaskResource(task='tts', model_format='onnx')
executor._init_from_path_onnx(am='fastspeech2_csmsc',voc='hifigan_csmsc',lang='zh')
@app.route("/api/tts", methods=["POST"])
def api_tts():
text = request.form['text'].strip()
st = time.time()
executor.infer_onnx(text=text,lang='zh',am='fastspeech2_csmsc')
name = '/tmp/'+str(uuid.uuid1())+'.wav'
executor.postprocess_onnx(name)
dt = time.time()-st
print("time cost: "+str(dt))
return send_file(name)
executor = TTSExecutor()
executor._init_from_path(am='fastspeech2_mix',voc='pwgan_aishell3',lang='mix')
@app.route("/api/tts", methods=["POST"])
def api_tts():
text = request.form['text'].strip()
st = time.time()
executor.infer(text=text,lang='mix',am='fastspeech2_mix',spk_id=174)
name = '/tmp/'+str(uuid.uuid1())+'.wav'
executor.postprocess(name)
dt = time.time()-st
print("time cost: "+str(dt))
return send_file(name)
测试数据是一段中英文混合文本:“1、英语,Hello friend.,2、汉语,你对于某个问 题没有调查,就停止你对于某个问题的发言权。这不太野蛮了吗?一点也不野蛮。你对那个问题的现实情况和历史情况既然没有调查,不知底里,对于那个问题的发言便一定是瞎说一顿。瞎说一顿之不能解决问题 是大家明了的,那末,停止你的发言权有什么不公道呢?许多的同志都成天地闭着眼睛在那里瞎说,这是共产党员的耻辱,岂有共产党员而可以闭着眼睛瞎说一顿的吗?”
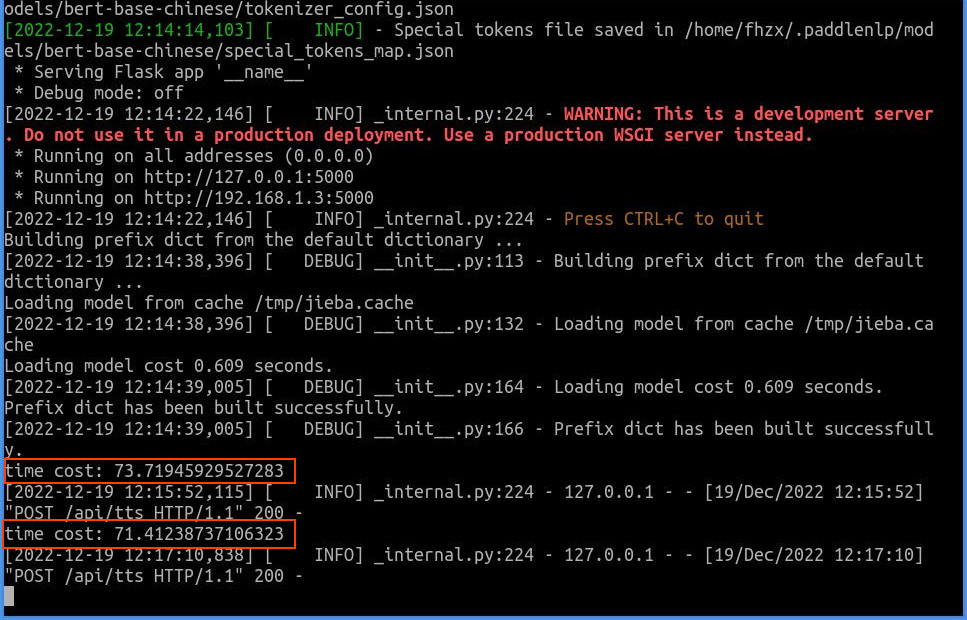
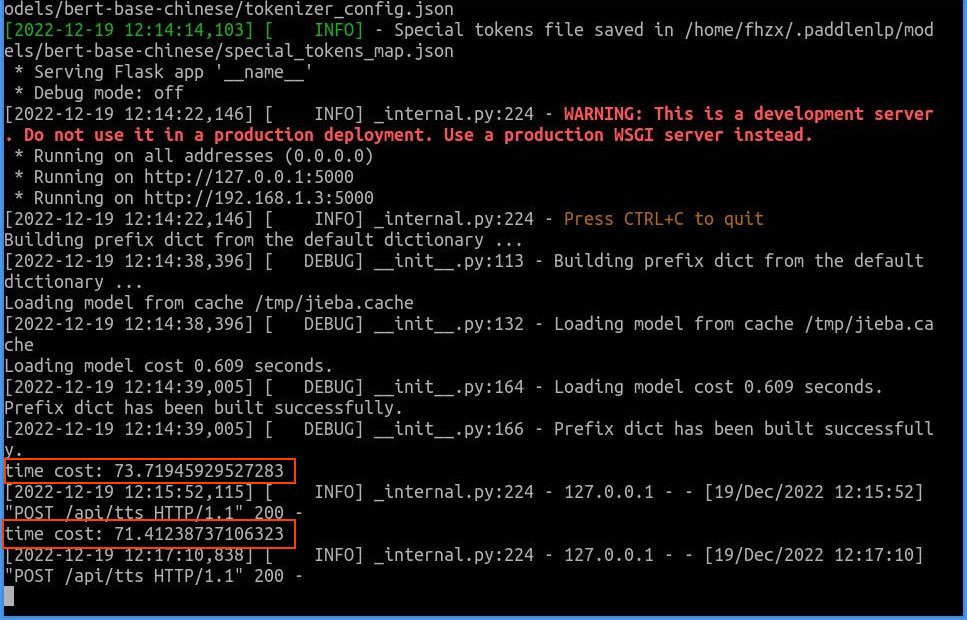
上面两张截图中,我在每张图上用红色方框标记了运行时间(time cost),可以看到:使用tts-onnx模式中文合成程序时,第一次耗费时间13.78秒,第二次耗费时间13.07秒;使用tts模式中英文混合合成程序时,第一次耗费时间73.72秒,第二次耗费时间71.41秒。比较2种模式的运行速度,可以得到一下结果:
上面的数据表明,实际部署时,直接使用tts模式中英文混合合成模型包性能非常低下,似乎不太合算,最好是自行将中英文混合文本按照中文、英文分段处理,全部使用onnx模式合成语音数据,然后按照原有顺序拼接起来。
本文相关代码:https://gitee.com/rocket049/paddlespeech-tts-server
