
单独或连续下载网页中的特定标题和正文
这个程序有两个版本:firefox扩展和chrome扩展,主要是用来下载网上的小说,也可以用来下载那些不让复制的网页内容。
项目网页:https://gitee.com/rocket049/content-receiver
firefox(火狐浏览器)扩展已经打包了,可以下载后从本地安装,google-chrome浏览器插件没有打包,可以用“调试模式”自行载入插件目录。
下面介绍用法:
第一步,点击扩展图标,找到article-picker
第二步,点击article-picker,显示弹出页
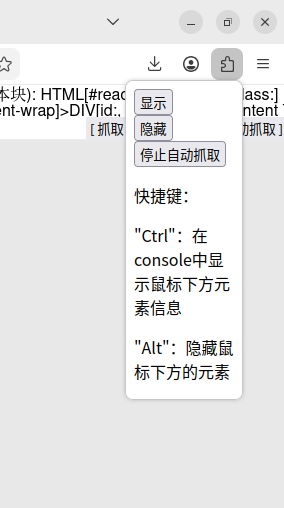
上面截图中有三个按钮和几行文字说明,点击第一个“显示”按钮就会在当前网页顶部显示下面内容:

点击第二个“隐藏”按钮,上图中的内容就会消失。
第三个“停止自动抓取”按钮对应上面图中的“自动”按钮,“自动”会启动连续下载“下一章”内容的功能,点击“停止自动抓取”取消自动连续下载。
下面是快捷键功能说明:
“Ctrl”按键的用法:把鼠标放在文字内容上,按“Ctrl”就会在网页顶部第二行显示HTML元素的路径和id、class信息,用于抓取信息。
“Alt”按键的用法:有些网站会有广告图片遮盖我们想看的内容,把鼠标放在图片上方,按“Alt”就会隐藏此图片,显示出图片下方的内容。
第三步,具体用法
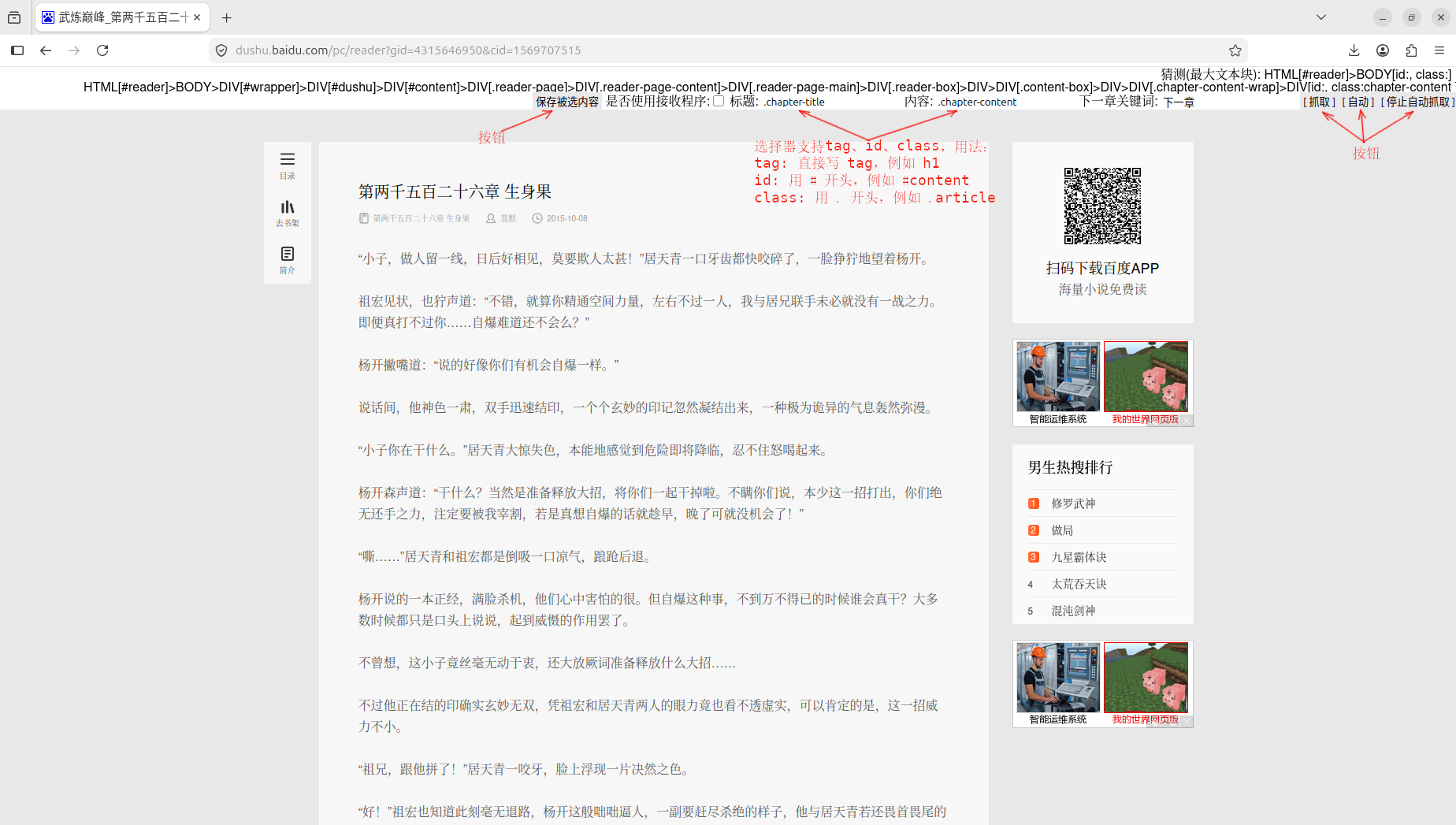
下面的说明以上图为例。
左侧按钮“保存被选内容”的用法:选定文字内容,点击此按钮,就会把选定的文字内容下载保存到“down-1781400159611.txt”这样的文件中。
右侧三个按钮的第一个“抓取”按钮的功能是根据“标题”和“内容”的HTML特征选择内容,并下载保存到“down-1781400159611.txt”这样的文件中。
第二个按钮“自动”就是连续下载,下载的内容和“抓取”按钮一样,下载当前内容后会模拟点击“下一章关键词”所对应的超链接或按钮,连续下载后续章节内容。在连续下载过程中点击“停止自动下载”就可以取消连续下载。
下面介绍“标题”和“内容”两个输入框怎么填写
这两个地方需要填写你想下载的文字内容的html的tag、id、class这三个特征之一。如果是唯一tag,就直接填tag,例如大标题一般都会是h1;如果是存在id,就填入#开头的id,例如#main-content;如果是唯一的className,就填入.开头的className,例如.article-content
查看办法就是用前面的“Ctrl”快捷键,把鼠标放到你要下载的内容上,按“Ctrl”后看顶部第二行显示的HTML路径信息。下面举两个例子:
大标题的路径如果显示这样:
HTML[#reader]>BODY>DIV[#wrapper]>DIV[#dushu]>DIV[#content]>DIV[.reader-page]>DIV[.reader-page-content]>DIV[.reader-page-main]>DIV[.reader-box]>DIV>DIV[.content-box]>DIV>DIV[.chapter-content-wrap]>H1[id:head-title, class:chapter-title]
最后一个tag是H1,它的id是head-title,class是chapter-title,如果大标题是唯一的,那么可以在“标题”输入框中填入:h1、#head-title或者.chapter-title。
文章内容的路径如果显示这样:
HTML[#reader]>BODY>DIV[#wrapper]>DIV[#dushu]>DIV[#content]>DIV[.reader-page]>DIV[.reader-page-content]>DIV[.reader-page-main]>DIV[.reader-box]>DIV>DIV[.content-box]>DIV>DIV[.chapter-content-wrap]>DIV[id:article-content, class:chapter-content ]
最后一个tag是div,它的id是article-content,class是chapter-content,div这个tag非常常用,所以不能作为内容的选择器,因此可以在“内容”输入框中填入:#article-content或.chapter-content。
